Debugging OpenLDAP ACLs
This article was posted by Matty on 2016-12-25 10:23:00 -0400 -0400
OpenLDAP provides a super powerful ACL syntax which allows you to control access to every nook and cranny of your directory server. When I’m testing advanced ACL configurations I have found it incredibly useful to add the “ACL” log option to the loglevel directive:
loglevel ACL
When this option is set slapd will show you how it applies the ACLs to a given LDAP operation:
Dec 4 09:01:00 rocco slapd[6026]: => acl_mask: access to entry "ou=users,dc=prefetch,dc=net", attr "entry" requested
Dec 4 09:01:00 rocco slapd[6026]: => acl_mask: to all values by "", (=0)
Dec 4 09:01:00 rocco slapd[6026]: <= check a_dn_pat: users
Dec 4 09:01:00 rocco slapd[6026]: <= check a_peername_path: 1.2.3.4
Dec 4 09:01:00 rocco slapd[6026]: <= acl_mask: [2] applying read(=rscxd) (stop)
Dec 4 09:01:00 rocco slapd[6026]: <= acl_mask: [2] mask: read(=rscxd)
Dec 4 09:01:00 rocco slapd[6026]: => slap_access_allowed: search access granted by read(=rscxd)
Dec 4 09:01:00 rocco slapd[6026]: => access_allowed: search access granted by read(=rscxd)
Dec 4 09:01:00 rocco slapd[6026]: => access_allowed: search access to "cn=matty,ou=users,dc=prefetch,dc=net" "uid" requested
This is super handy and will save you tons of time and heartburn when crafting complex ACLs.
Troubleshooting vSphere NSX manager issues
This article was posted by Matty on 2016-12-25 10:08:00 -0400 -0400
This week I installed VMWare NSX and created a new NSX manager instance. After deploying the OVF and prepping my cluster members I went to create the three recommended controller nodes. This resulted in a “Failed to power on VM NSX Controller” error which didn’t make sense. The package was installed correctly, the configuration parameters were correct and I double and tripled checked that the controllers could communicate with my NSX manager. NSX manager provides appmgmt, system and manager logs which can be viewed with the show utility:
nsx> show log manager follow
To see what was going on I tailed the manager log and attempted to create another controller. The creation failed but the following log entry was generated:
inherited from com.vmware.vim.binding.vim.fault.InsufficientFailoverResourcesFault:
Insufficient resources to satisfy configured failover level for vSphere HA.
I had a cluster node in maintenance mode to apply some security updates so this made total sense. Adding the node back to the cluster allowed me to create my controllers without issue.
Importing and mounting ZFS pools at boot time on Fedora servers
This article was posted by Matty on 2016-12-23 12:20:00 -0400 -0400
If you read my blog you know I am a huge fan of the ZFS file system. Now that the ZFS on Linux project is shipping with Ubuntu I hope it gets more use in the real world. Installing ZFS on a Fedora server is relatively easy though I haven’t found a good guide describing how to import pools and mount file systems at boot. After a bit of digging in /usr/lib/systemd/system/ it turns out this is super easy. On my Fedora 24 server I needed to enable a couple of systemd unit files to get my pool imported at boot time:
$ systemctl enable zfs-mount.service
$ systemctl enable zfs-import-cache.service
$ systemctl enable zfs-import-scan.service
Once these were enabled I rebooted my server and my pool was up and operational:
$ zpool status -v
pool: bits
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
bits ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ata-WDC_WD7500AACS-00D6B1_WD-WCAU47102921 ONLINE 0 0 0
ata-WDC_WD7500AACS-00D6B1_WD-WCAU47306478 ONLINE 0 0 0
ata-WDC_WD7500AACS-00D6B1_WD-WCAU47459778 ONLINE 0 0 0
ata-WDC_WD7500AACS-00D6B1_WD-WCAU47304342 ONLINE 0 0 0
errors: No known data errors
$ df -h /bits
Filesystem Size Used Avail Use% Mounted on
bits 2.0T 337G 1.7T 17% /bits
The future is looking bright for ZFS and I hope the Linux port will become rock solid as more people use it.
Creating Bind query log statistics with dnsrecon
This article was posted by Matty on 2016-11-11 14:27:00 -0400 -0400
A month or two back I was investigating a production issue and wanted to visualize our Bind query logs. The Bind statistics channel looked useful but there wasn’t enough data to help me troubleshoot my issue. In the spirit of software re-use I looked at a few opensource query log parsing utilities. The programs I found used MySQL and once again they didn’t have enough data to fit my needs. My needs were pretty simple:
- Summarize queries by record type
- Show the top # records requested
- Show the top # of clients querying the server
- Print DNS query histograms by minute
- Print DNS query histograms by hour
- Have an extended feature to list all of the clients querying a record
- Allow the records to be filtered by time periods
Instead of mucking around with these solutions I wrote dnsrecon. Dnsrecon takes one or more logs as an argument and produces a compact DNS query log report which can be viewed in a terminal window:
$ dnsrecon.py logs/ --histogram
Processing logfile ../logs/named.queries
Processing logfile ../logs/named.queries.0
Processing logfile ../logs/named.queries.1
Processing logfile ../logs/named.queries.2
Processing logfile ../logs/named.queries.3
Processing logfile ../logs/named.queries.4
Processing logfile ../logs/named.queries.5
Processing logfile ../logs/named.queries.6
Processing logfile ../logs/named.queries.7
Processing logfile ../logs/named.queries.8
Processing logfile ../logs/named.queries.9
Summary for 05-Nov-2016 10:31:36.230 - 08-Nov-2016 14:15:51.426
Total DNS_QUERIES processed : 9937837
PTR records requested : 6374013
A records requested : 3082344
AAAA records requested : 372332
MX records requested : 32593
TXT records requested : 23508
SRV records requested : 19815
SOA records requested : 19506
NS records requested : 6661
DNSKEY records requested : 2286
Top 100 DNS names requested:
prefetch.net : 81379
sheldon.prefetch.net : 75244
penny.prefetch.net : 54637
.....
Top 100 DNS clients:
blip.prefetch.net : 103680
fmep.prefetch.net : 92486
blurp.prefetch.net : 32456
gorp.prefetch.net : 12324
.....
Queries per minute:
00: ******************* (149807)
01: ******************* (149894)
02: ******************************* (239495)
03: *********************************************** (356239)
04: ********************************************** (351916)
05: ********************************************* (346121)
06: ************************************************ (362635)
07: ************************************************** (377293)
08: ********************************************* (343376)
.....
Queries per hour:
00: ********* (325710)
01: ********** (363579)
02: ******** (304630)
03: ******** (302274)
04: ******** (296872)
05: ******** (295430)
.....
Over the course of my IT career I can’t recall how many times I’ve been asked IF a record is in use and WHO is using it. To help answer that question you can add the “–matrix” option to print domain names along with the names / IPs of the clients requesting those records. This produces a list similar to this:
prefetch.net
|-- leonard.prefetch.net 87656
|-- howard.prefetch.net 23456
|-- bernadette.prefetch.net 3425
The top entry is the domain being requested and the entries below it are the clients asking questions about it. I’m looking to add the record type requested to the resolution matrix as well as –start and –end arguments to allow data to be summarized during a specific time period. Shoot me a pull request if you enhance the script or see a better way to do something.
Installing NVidia binary drivers on an Ubuntu 16.10 desktop
This article was posted by Matty on 2016-11-11 12:36:00 -0400 -0400
I recently upgraded my Ubuntu 16.10 desktop with an NVidia GeForce 730 graphics adapter. My experiences with the nouveau opensource driver haven’t been good so I decided to install the binary drivers from NVidia. Ubuntu makes this process INCREDIBLY easy. To install the latest NVidia drivers you can click the “Search your Computer” icon in the Unity menu, type in “Drivers” and then click additional drivers. That should present you with a screen similar to the following”
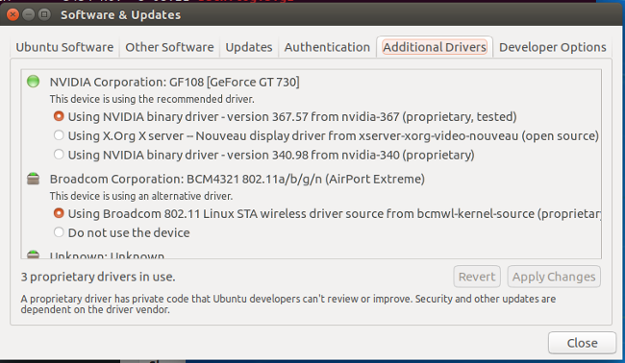
Clicking “Using NDIVIA Binary Driver” and then “Apply Changes” should load the correct driver for your card. Once the driver loads and your X11 configs are updated you should be able to reboot into a desktop environment that is powered by the NVidia closed source graphics driver. So far it’s working well!